El resumen del día
RAG híbrido, ingeniería de bucles y la nueva piel del desarrollo GenAI: qué cambia para producto y equipo
Recogemos las piezas clave que están reconfigurando cómo construimos y gobernamos aplicaciones con modelos: un tutorial práctico para combinar búsquedas semánticas y por palabras clave, una guía de Python pensada para ingenieros GenAI, avances en evaluación de modelos de recompensa, y dos ideas que cambian el día a día de los equipos: abandonar la ingeniería de prompts como práctica única y añadir una capa de gobernanza (loop engineering) a los agentes. Todo con foco en costes, fiabilidad y producción.
Hibridar recuperadores para que RAG deje de fallar
Un tutorial paso a paso nos muestra cómo construir un RAG híbrido combinando FAISS, BM25, LangGraph y Claude Sonnet 4.6. El aprendizaje clave: los retrievers densos hallan similitudes semánticas pero fallan en coincidencias exactas; BM25 acierta en matches literales pero no entiende el significado. La solución práctica es ejecutar ambos en paralelo y fusionar resultados (por ejemplo, Reciprocal Rank Fusion). Para producto y negocio esto implica mayor precisión en respuestas críticas —contratos, cifras o códigos— y menor riesgo de respuestas confiadas pero erróneas, aunque con coste y complejidad de infra aumentados.
Python para el desarrollador Generative AI: lo que realmente importa
Un compendio técnico orientado a ingenieros GenAI prioriza conceptos prácticos: async/await para escalado y streaming en tiempo real, patrones de memoria para datasets masivos y técnicas para integrar APIs de embeddings y vDB. Para equipos, esto traduce en decisiones de arquitectura que reducen latencia y costes unitarios por petición, y en perfiles de hiring que valoran asincronía y manejo de I/O sobre trucos de sintaxis.
Los modelos son más que 'autocomplete'
Un artículo técnico explica cómo la producción de texto por transformers se apoya en un estado interno rico, no solo en la predicción de un token tras otro. Este marco mental cambia cómo diseñamos prompts, tests de robustez y métricas: si el modelo mantiene un estado semántico, las fallas no siempre son superficiales y requieren estrategias de verificación más profundas para evitar costes reputacionales o impactos operativos.
Reward models: entrenar en conjunto de datos no equivale a aprender valores
Un estudio de NUS, VinUniversity y NTU revela que buenos resultados in-distribución en modelos de recompensa no garantizan transferencia fuera de distribución. Usando RAIL como benchmark, los autores muestran que los modelos tienden a aprender las peculiaridades del dataset y proponen Representation Anchoring para penalizar el drift de representación respecto al modelo preentrenado. Para equipos que deployan reward models, esto es una llamada a reforzar validación OOD y a incluir anclajes que reduzcan riesgos de comportamiento inesperado en producción.
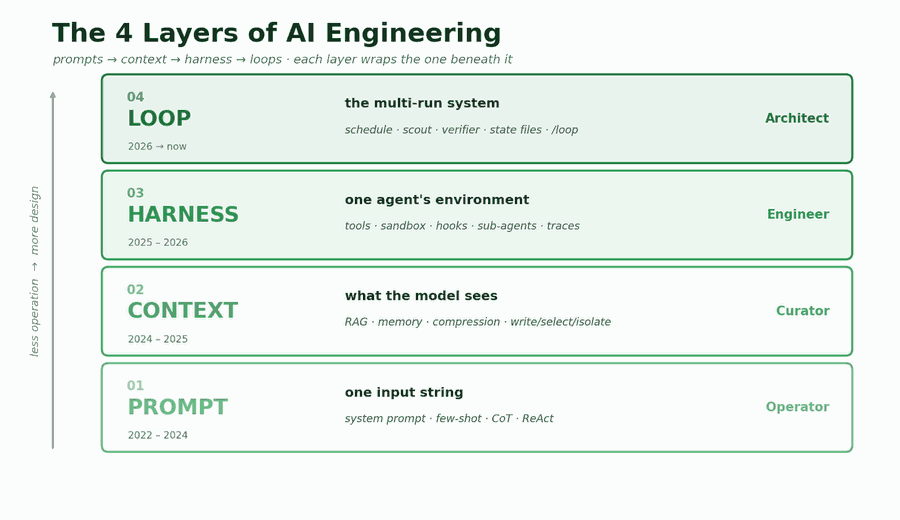
Adiós a la ingeniería de prompts sola: capas que reemplazan prompts
Una pieza sobre prácticas de vanguardia señala que los mejores ingenieros han dejado de depender exclusivamente de prompts; en su lugar, organizan sistemas en múltiples capas (loops, controladores, evaluadores, memoria) que automatizan y repiten interacciones con el modelo. Esto eleva la productividad y reduce costes operativos al sistematizar patrones repetibles, pero exige inversión en infraestructura y en pruebas de regresión del comportamiento.
Loop Engineering: gobernanza imprescindible para agentes que actúan
La propuesta de Loop Engineering plantea que cuanto más inteligente es un agente, mayor es el daño potencial antes de detectar fallos. Recomienda introducir un gobernador, un evaluador y un botón de parada de emergencia para tareas que interactúan con sistemas de producción. En práctica esto significa añadir monitoreo continuo, políticas de rollback y límites operacionales, medidas que mitiguen riesgos legales y costes por incidentes en entornos productivos.
Qué nos llevamos para producto y equipo
Integrar retrievers híbridos mejora la precisión frente a casos críticos; invertir en Python asíncrono y patrones de ingeniería reduce latencia y costes; evaluar reward models fuera de la distribución y anclar representaciones protege contra comportamientos no deseados; y diseñar capas de gobernanza (loop engineering) es ya imprescindible para cualquier agente que actúe sobre sistemas reales. En conjunto, estas tendencias marcan la hoja de ruta técnica y de gobernanza para desplegar IA útil y segura en producto.
Analizado hoy...
Estas son las noticias analizadas hoy, a las que puedes acceder para conocer más detalle.
Construye un sistema RAG híbrido con FAISS, BM25, LangGraph y el modelo Claude Sonnet
Every Python Concept a Generative AI Developer Actually Needs to Know
Why ChatGPT Is More Than Autocomplete
Enseñar para el examen: por qué los modelos de recompensa aprenden el conjunto de datos, no los valores